

Us Open Tennis Prize Money Each Round
Tennis Prize Money Data Harvesting Using Selenium
Multi-Page Web Scraping by Utilizing Patterns and Waits in Selenium
![]()

Introduction
This tutorial piece will detail how to exploit patterns to iterate through the Top 200 Men's Tennis Players who currently compete on the ATP Tour Circuit.
Specifically, for each of the players, I would like to extract their respective name, age and their Prize Money as of 29/07/2019. The web scraping will be performed using the Selenium module, and will utilize some useful Classes from this module, which will ensure that the codes run more efficiently.
In this example, player n ame and age are on the same web-page, but their respective prize money earnings are on a separate page, unique to each player.
Through the utilization of the Selenium module, this information can be acquired.
Getting started and Pattern Searching
To begin, I first import the webdriver from the Selenium module. I then create a web driver object and assign it to the variable browser. Following this, I simply navigate to the ATP Tour web page as shown below.
Now that the appropriate web page has been loaded, I can clearly see a list of the Top 100 Men's singles players (in the image below, only the first 11 are shown, but scrolling down to the bottom reveals the first 100 players).
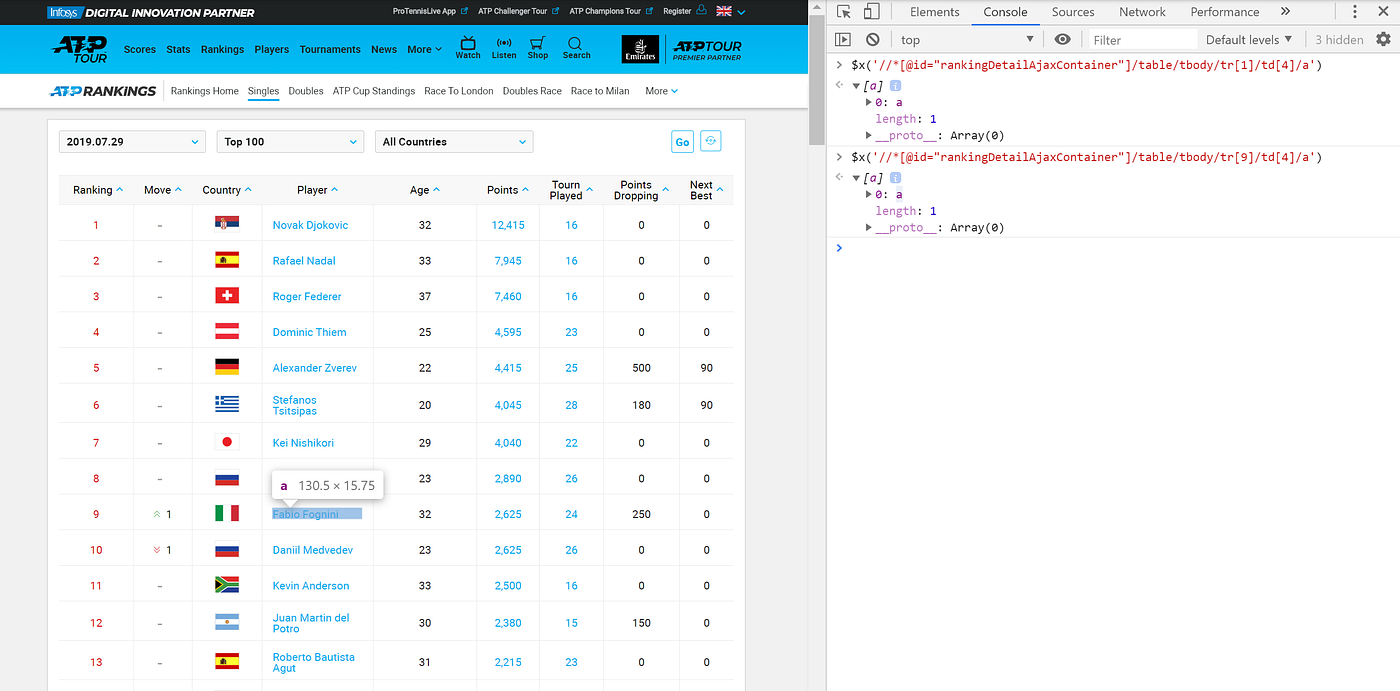
To iterate through the first 100 players, I need to find some consistency in the data organisation. Specifically, when I right-click, select inspect and hover over the player name, I can copy the Xpath.

I then paste this Xpath into the console tab in the developers tools in Chrome. When I first copy and paste the Xpath for Novak Djokovic, I can see that the players corresponds to table row 1, tr[1], and table data 4, td[4]. By checking other players, for example Fabio Fogini as highlighted below, I can see that the only portion of the Xpath that changes is the table row number, tr[9].
This makes sense as the data is organised into a Tabular format, and therefore has the consistency that I can exploit. To make use of this feature, I can simply replace the number in the tr portion of the Xpath, and iterate through all the player names using a range from 1 (inclusive) to 101 (exclusive)!
I exploit the same relationship to extract the players age, but on this occasion the table data, td is in column 5.
Code Workflow
I would like my code to work as follows:
- Go to the main rankings page, find the individual player name and age starting with the Top ranked player and extract this information.
- Click on the link for each player, starting with the highest ranked player, and extract their prize money so far this year (as of 29/07/2019).
- Navigate back to the main rankings page and repeat steps 1 and 2 for the first 100 players.
- Once the data has been acquired for the first 100 players, click onto the next page, with players ranked between 100–200, and repeat steps 1 and 2.
- Once this information has been acquired, stop iterating and write the output to Excel for downstream data manipulation and validation.
Webdriver Wait and Expected Conditions Work Together
When a page is loaded by the browser, the elements within that page may load at different time intervals. This makes locating elements difficult: if an element is not yet present in the DOM, a locate function will raise an ElementNotVisibleException exception. Using waits, we can solve this issue.
An explicit wait makes WebDriver wait for a certain condition to occur before proceeding further with execution.
To make the code more robust, I will instruct the code to wait until the web elements are either located or clickable before any actions should be performed on them. Below are 2 important selenium classes sourced from: https://seleniumhq.github.io/selenium/docs/api/py/api.html.
Both the WebDriverWait and the expected_conditions can be used together. In the expected conditions example listed below, I would wait for the visibility an an element to be located.
class selenium.webdriver.support.wait.WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
class selenium.webdriver.support.expected_conditions.visibility_ of_element_located(locator)
How to use Webdriver Wait with Expected Conditions.
The WebDriverWait takes 2 required parameters, namely a driver, in my case I called the driver, browser, and a timeout. A timeout indicates how long to wait before throwing a timeout exception if the respective web element cannot be located.
Lets dissect an example.
I want to extract the player name which has the Xpath below
'//*[@id="rankingDetailAjaxContainer"]/table/tbody/tr[1]/td[4]/a'
I write WebdriverWait, followed by my driver called browser, then a time to wait up until of 20 seconds. I then tell the webdriver to wait until the element is visible, by appending visibility_ of_element_located to expected_conditions. I then specify a locator using By.XPATH (in capitals) , followed by the appropriate Xpath in quotations.
The addition of the wait, adds an extra checking step in the script. This is particularly useful when switching between web pages in a for loop as the web elements may take a little while to load.
Combining these core ideas can now lead to the creation of a for loop with a range of 1 to 101, to gather data on the first 100 players on each page.
When the player and age have been extracted using the .text function, the code then instructs the browser to click on the link for each player and extract their prize money. Here, instead of extracted the player name through the .text function, I click on their name using the .click() method, as shown in the code below. As each player is in the same row, I can use the pattern I found before for all the unique links for the player stats page.
The prize money for each player can simply be found by copying the Xpath. for each player the data is uniformly organised, therefore this Xpath will work for each player on each iteration of the for loop.
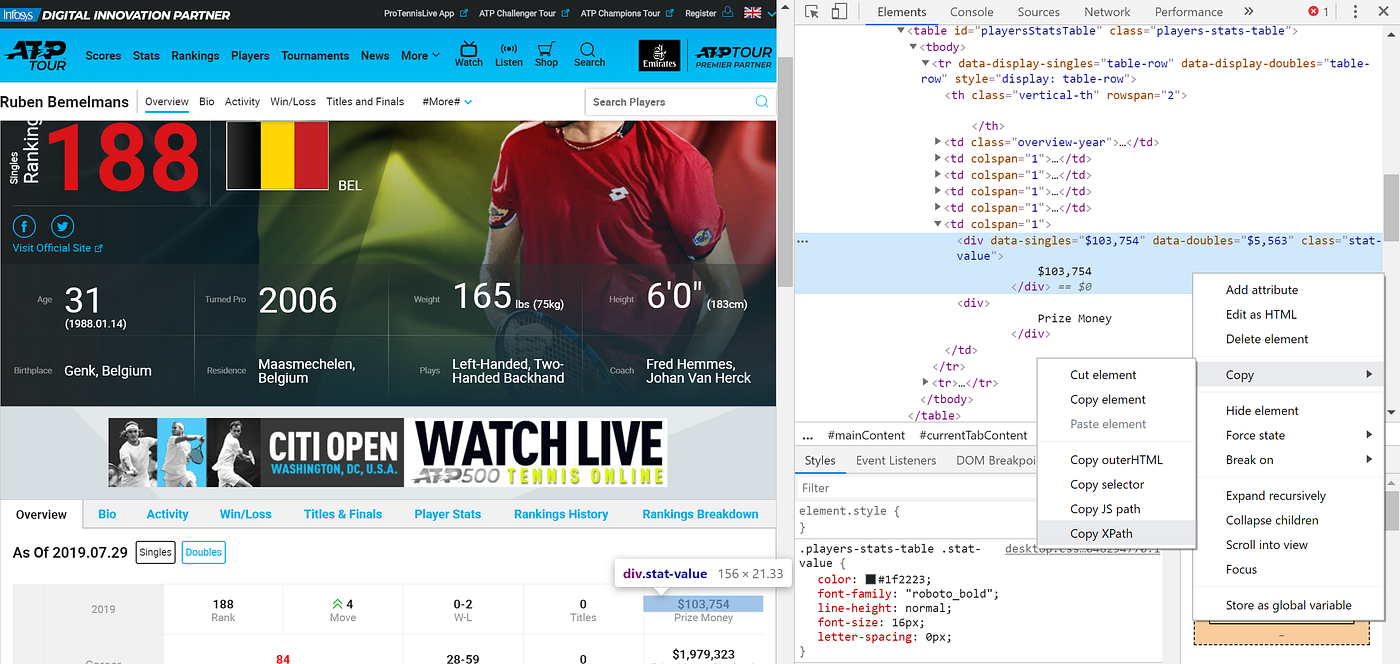
Once this has been achieved I navigate back to the singles ranking page and extract the name and age and earning for the second ranked player. At each iteration of the for loop I append data to lists for Tennis_player, Age, and Prize_money_2019.
When data for the first 100 players have been scraped, I navigate onto the next page, again, checking that the button to do this is present on the web page and is clickable. The condition in the while loop tells the code which singles page to go back to.
When the 2 iterations of the while loop are complete, I write the data to an Excel file using pandas, by creating a DataFrame and zipping my lists together, and giving them sensible columns names.
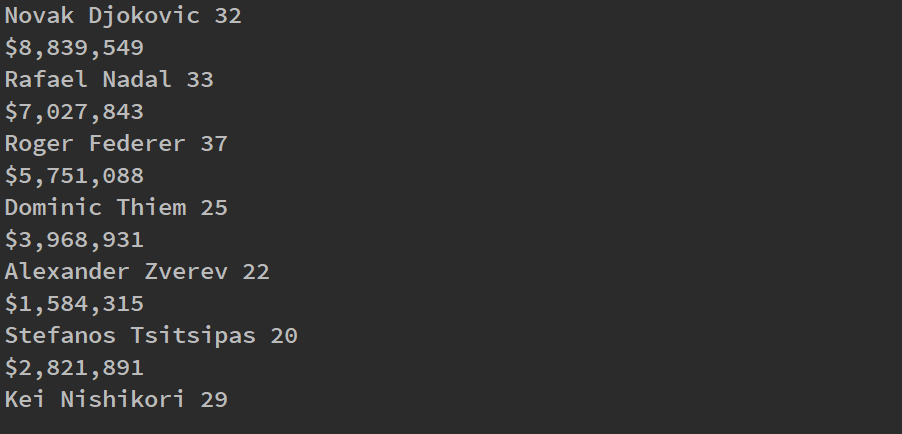
For clarification that the script was running smoothly, on each iteration, I printed the player, and their age and prize money. This is not necessary, but gave me a visual inspection on the progress of the iterations. An example of how this output looks in the console is shown below.
Validation
To finish, it is important to validate that the code worked as intended. For example, I will check 3 players to showcase that the correct data has been acquired. Firstly, lets confirm, Novak Djokovic's Prize money was $8,839,549 by looking through my Excel file, 'Tennis_Player_Earnings'.
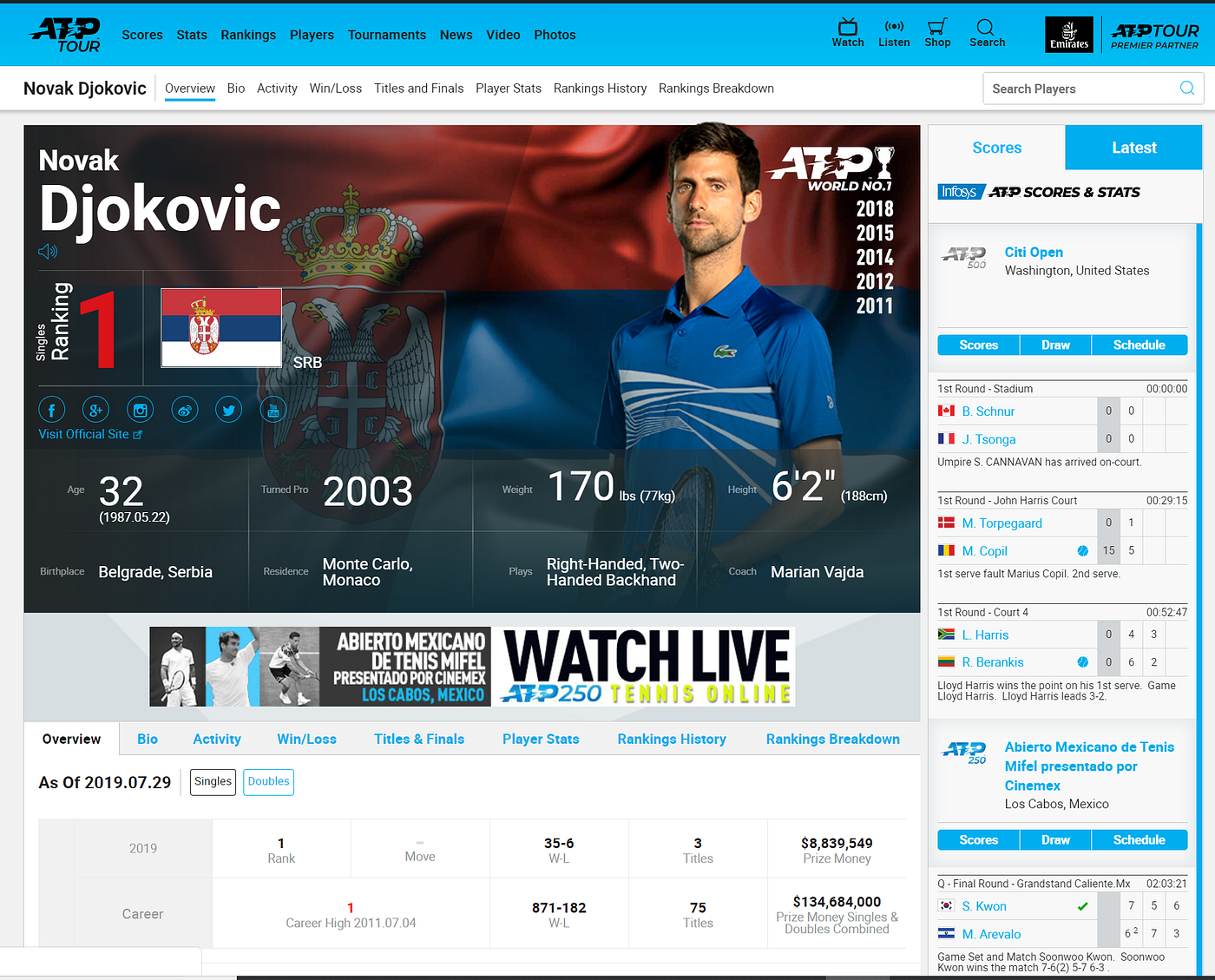
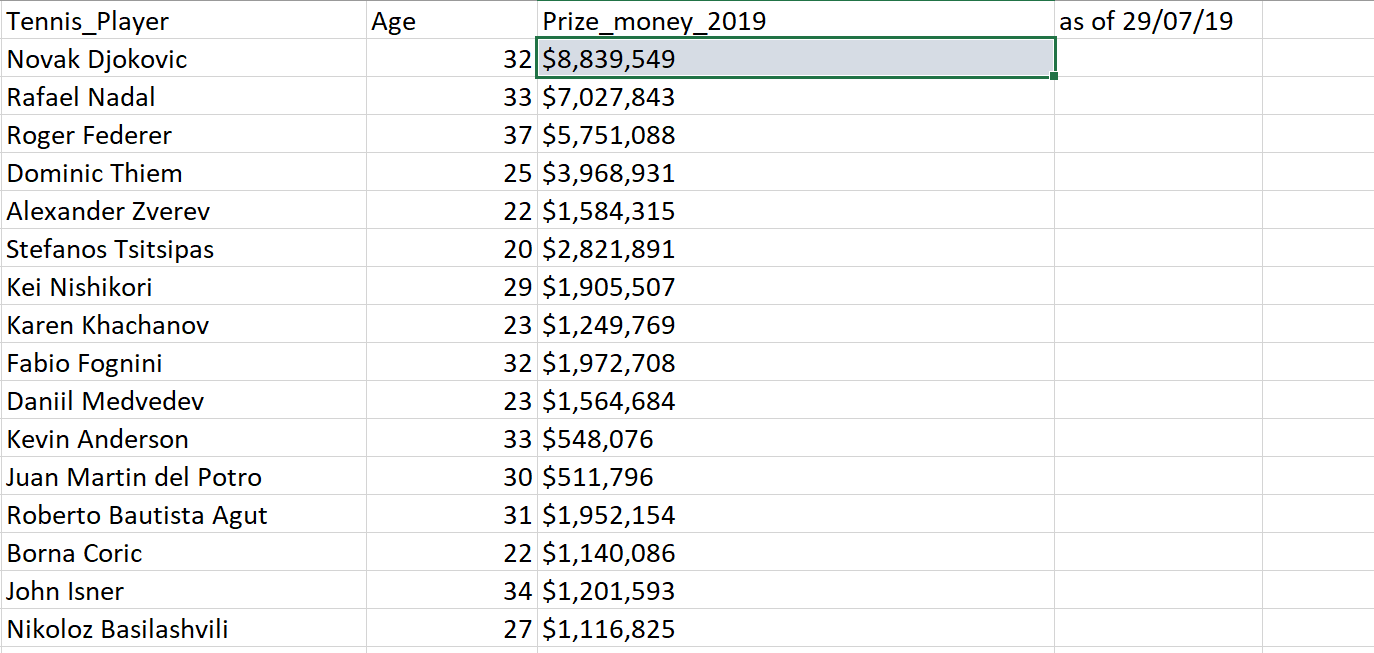
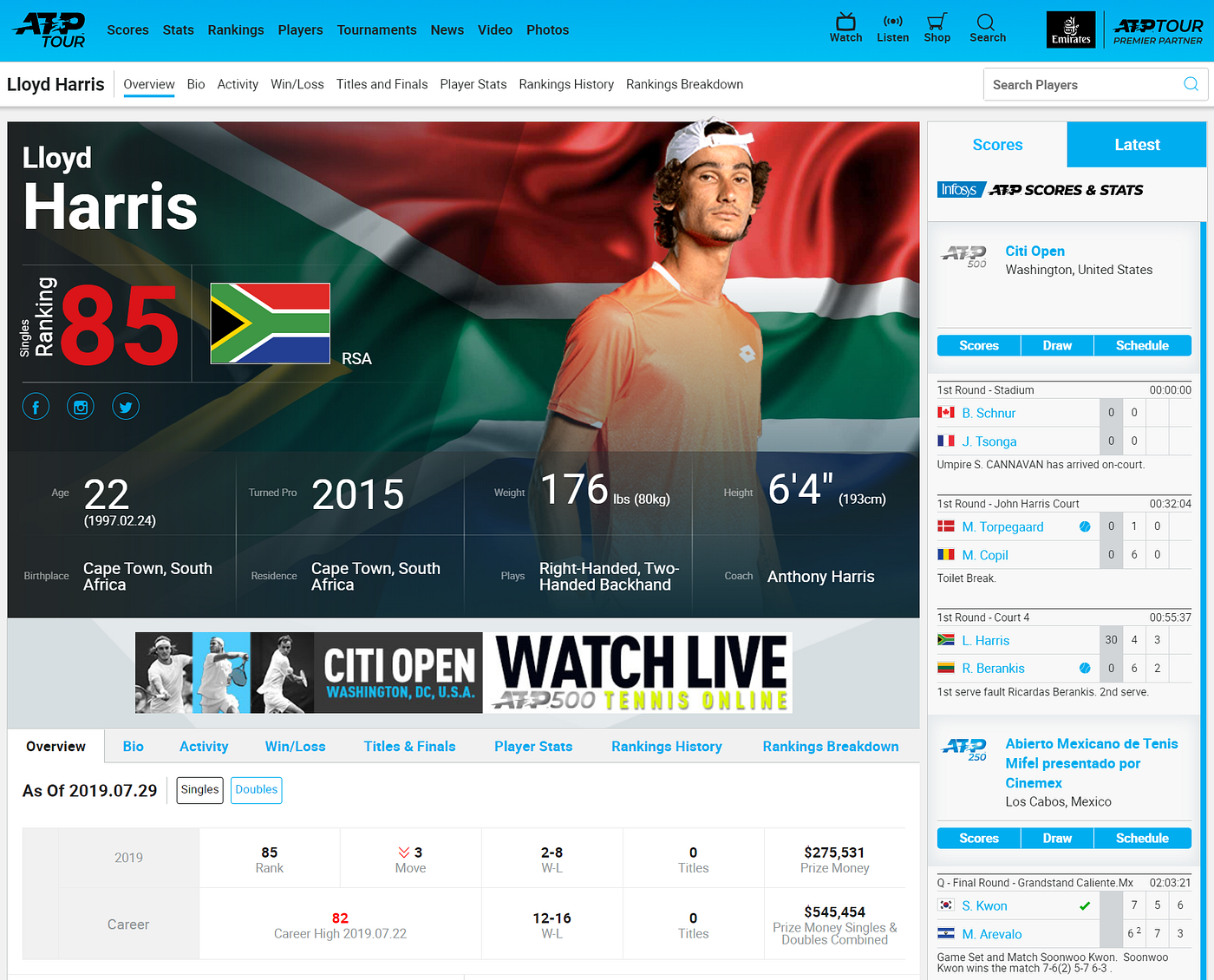
Success! Lets now check again with another player, namely Lloyd Harris. His Prize money should be $275,531.
It seems Lloyd has a way to go, before rivaling Novak for Prize money!
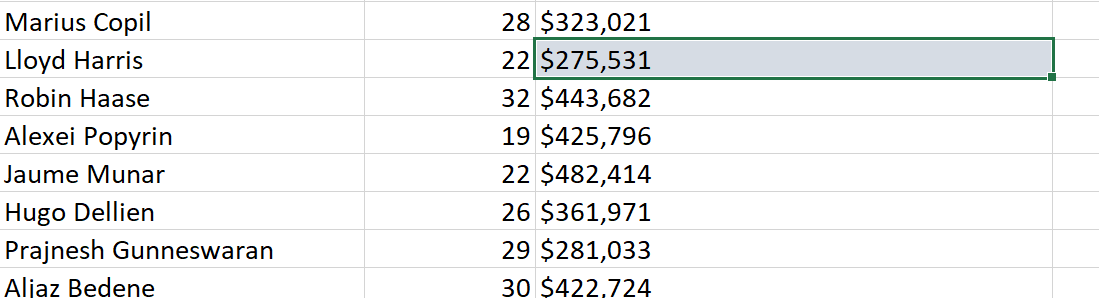
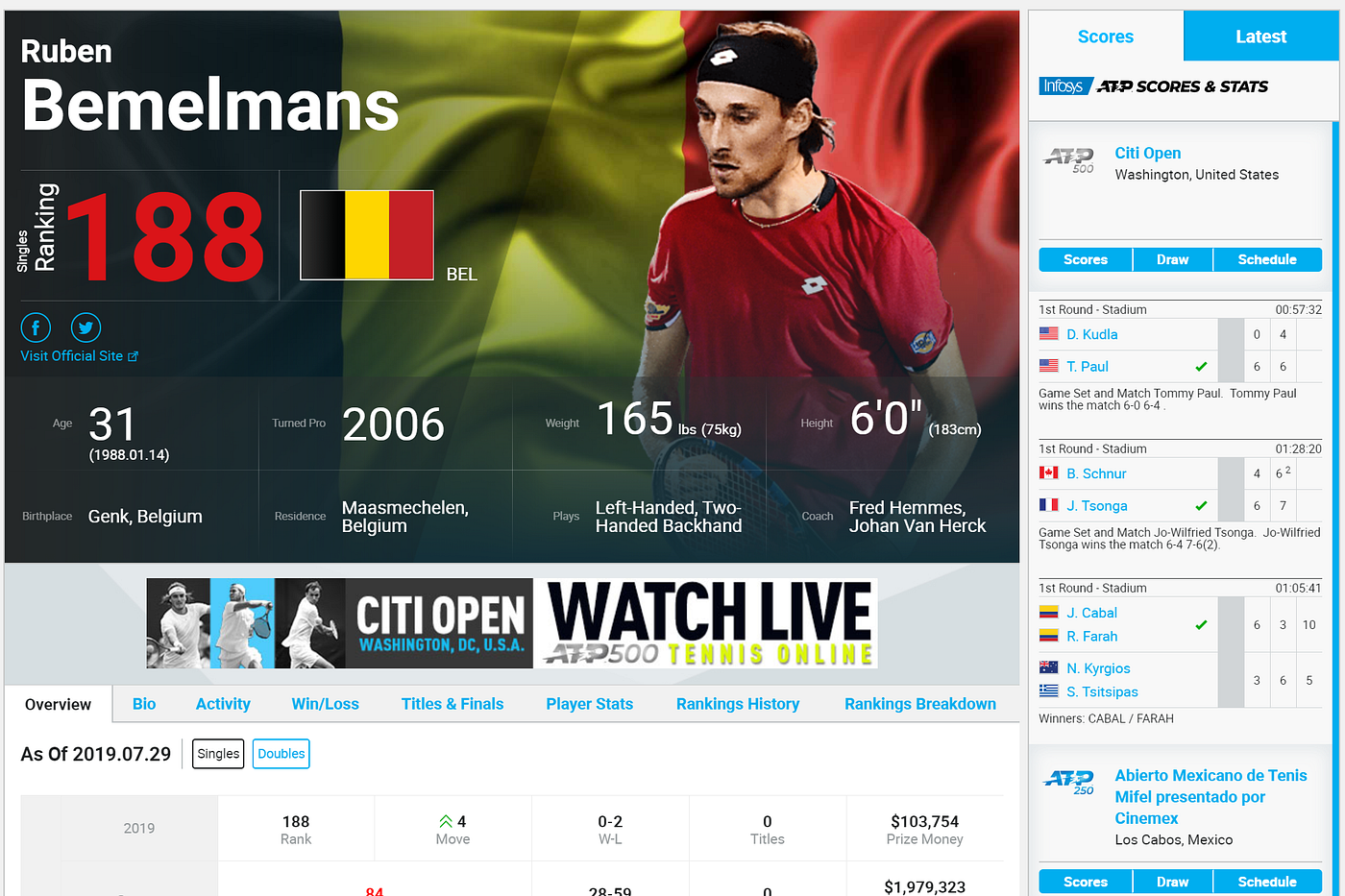
To confirm once more, I should check that a player from the second page, i.e. ranked between 100–200 has the correct prize money attached to them. 188th ranked, Ruben Bemelmans should have earned $103,754 in Prize money. This would confirm that the click to the next page worked as intended! Again, the information is correct.

The code automatically iterates through the Tennis Players and their Prize money on a separate page, accessible through he link on their name. Watching the automatic web iterations in real-time shows how the process works. To demonstrate, a video displaying the iteration through the first 3 players is depicted.
Summary
This example has illustrated that by finding patterns and exploiting them, and by waiting for web elements to load and populate the web pages, we can extract information without common element location errors. However, as a caution, the patterns were found using Xpaths.
If the organizers of this page decided to add a column or move player names to another column, the script would break, so be careful when using Xpaths and try to use CSS selectors where possible. However, if you are writing a quick script like this one, and output the data to Excel, the approach shown should suffice, however do not expect it to work X month's down the line.
Us Open Tennis Prize Money Each Round
Source: https://towardsdatascience.com/tennis-prize-money-data-harvesting-using-selenium-c38b79323d47
Posted by: moorepallarcups96.blogspot.com
0 Response to "Us Open Tennis Prize Money Each Round"
Post a Comment